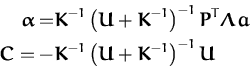- ...
itself.1
- This is a reasonable assumption if we want to extract
information from the data, or equivalently we want to have
predictions based on the dataset. A uniform distribution of the data
would be completely non-informative.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... Gaussians2
- I acknowledge D. Saad
for pointing it out. It turns out however, by studying the
KL-distance between the original and a slightly perturbed density
function, that the KL-distance only relates to the diagonal elements
of the Fisher information matrix, this in fact is an
exercise[14, page 334].
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ...SchoBurSmo99.3
- A
dedicated internet page is at: www.kernel-machines.org
containing tutorials for the SVM.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ....4
- The data in the feature space
are considered as having zero mean. Subtracting the mean would not
lead to conceptual difference, it has been ignored for clarity.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ...
is:5
- There might be no exact inverse for
Kmm, this is
solved by adding a ``jitter'' factor to the diagonal elements in the
original kernel matrix making sure it is positive definite.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... code.6
- The operations in eq. (130) might involve inversions of almost singular matrices. A possible way to deal with the singular matrices to introduce the auxiliary matrix
U = PT
 P and to rewrite eq. (130) as:
P and to rewrite eq. (130) as:
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ...
price.7
- Available from http://lib.stat.cmu.edu/boston.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ...Ripley96 8
- Available at http://www.stats.ox.ac.uk/pub/PRNN
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ...GormanSejnowski88.9
- Available from http://www.ics.uci.edu/
 mlearn/MLRepository
mlearn/MLRepository
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ...
patterns.10
- Available from http://www.kernel-machines.org/data/
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ...
parameters.11
- The introduction of
 , a parameter to be
estimated from the data, in the structure of the prior GP
makes the esetimation not consistent with the Bayesian framework.
This is not a problem in this section since we are using MAP
approximations to the density function.
, a parameter to be
estimated from the data, in the structure of the prior GP
makes the esetimation not consistent with the Bayesian framework.
This is not a problem in this section since we are using MAP
approximations to the density function.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.